Imagine a world where machines completely reshape how we do math. Such machines will need to first harness the vast literature amassed by human mathematicians over the centuries. They will need to bridge ideas and unify knowledge—generalizing examples and uncovering the hidden structures behind them.
\( \frac{4}{\pi} = 1 + \frac{1}{3 + \frac{4}{5 + \frac{9}{7 + \frac{16}{\cdots} } } } \quad \) Gauss 1813 \( \quad \quad \quad \quad \quad \) \( \frac{4}{\pi – 2} = 3 + \frac{3}{5 + \frac{8}{7 + \frac{15}{9 + \frac{24}{\cdots} } } } \quad \) Ramanujan Machine 2021
Is there a hidden connection?
Our project develops the first pipeline for unification of mathematical knowledge, which we demonstrated on a hallmark problem: formulas for the constant \(\pi\). We also show that as a result, novel math can emerge—exemplified by automated proofs of previously unknown connections. Using large language models (LLMs) for data harvesting and novel symbolic algorithms for proof discovery, we automatically scan hundreds of thousands of arXiv papers for \(\pi\) formulas, extracting hundreds of unique formulas, and uncover rigorous connections between 94% of them. This method further shows that the recently discovered Conservative Matrix Field (CMF) contains at least 43% of the formulas, thus unifying the knowledge within them.

Harvesting formulas with LLMs
A multi-stage pipeline collects and validates formulas for the constant of interest—\(\pi\)—from hundreds of thousands of papers. Regexes sift through equations, collecting constant-computing patterns. These formulas are then passed to GPT-4o mini for classification (determining the type of the formula) and translation into SymPy code (GPT-4o). Each formulas’ convergence to an expression containing \(\pi\) is numerically validated, thus complementing the LLM and sparing it the burden of symbolic manipulation.


Recurrences as universal representations of formulas
Recurrences capture many formulas in number theory, from products to continued fractions and series
\( \frac{\pi}{2} = \prod_{k=1}^\infty \left( \frac{2k}{2k – 1} \cdot \frac{2k}{2k + 1} \right)
\quad \Rightarrow \quad
a_n = a_{n-1} \left( \frac{2n}{2n – 1} \cdot \frac{2n}{2n + 1} \right) \quad ; \quad a_1 = \frac{2}{3} \)
\( \frac{\pi}{2} = \lim_{n \to \infty} a_n \)
\( \frac{4}{\pi} = 1 + \frac{1^2}{3 + \frac{2^2}{5 + \frac{3^2}{7 + \frac{4^2}{9 + \frac{5^2}{ \cdots}}}}} \quad \Rightarrow \quad \begin{pmatrix} p_{n-1} & p_n \\ q_{n-1} & q_n \end{pmatrix} = \begin{pmatrix} p_{n-2} & p_{n-1} \\ q_{n-2} & q_{n-1} \end{pmatrix} \begin{pmatrix} 0 & n^2 \\ 1 & 2n + 1 \end{pmatrix} \quad ; \quad \begin{pmatrix} p_{-1} & p_0 \\ q_{-1} & q_0 \end{pmatrix} = \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix} \)
\( \frac{4}{\pi} = \lim_{n \to \infty} \frac{p_n}{q_n} \)
\( \frac{\pi}{4} = \sum_{k=0}^\infty \frac{(-1)^k}{2k + 1} \quad \Rightarrow \quad x_n = \left(1 – \frac{2n – 1}{2n + 1}\right) x_{n-1} + \frac{2n – 1}{2n + 1} x_{n-2} \quad ; \quad x_0 = 1, x_1 = \frac{2}{3} \)
\( \frac{\pi}{4} = \lim_{n \to \infty} x_n \)
We call the simplest recurrence for a formula its canonical form, and conversion to this standard representation unifies some formulas that look unrelated at first. Here, we use a tool by the Research Institute for Symbolic Computation (RISC) to find the minimal recurrence representing each formula. Since order-2 recurrences are equivalent to continued fractions, we adopt this prism and use the formulation of continued fractions to deal with all such recurrences. When polynomial, these are denoted PCF for polynomial continued fractions. The prevalence and power of recurrences for describing formulas raises a potent question: can formulas in number theory be unified under a single umbrella using recurrences as a framework?
The matching algorithm: \(\delta\) + folds + coboundary
Representing formulas via their recurrences, our algorithm uses numerical evaluations of “dynamical metrics” of formulas to cluster formulas and suggest equivalence between formula pairs. We then use a novel symbolic algorithm to find the precise, reversible transformation between the two target formulas. The matching algorithm has two steps: folding and UMAPS (Unification via Mapping Across Symbolic Structures)—a novel symbolic algorithm for solving coboundary equivalences.
\(\delta\) for discovery
The first stage takes advantage of a key property of the irrationality measure (\(\delta\)), using it to cluster formulas and indicate formula equivalence
\(\delta = -1 – \lim_{n\to\infty} \log_{\tilde{q}_n} |\frac{p_n}{q_n} – L| \)
where \(\frac{p_n}{q_n}\) is the nth approximant generated by a mathematical formula for the constant of interest, \( L \) is its limit, and \( \tilde{q}_n \) is the reduced denominator \(\tilde{q}_n = \frac{q_n}{gcd(p_n, q_n)}\). Formula pairs with similar \( \delta \) are sent to the next step.
Folding
Folding is intended to resolve the common case where one formula generates a regular subsequence of another formula: a fold by k converts the sequence \(a_n\) to the sequence \(a_{kn}\). This closed-form algebraic transformation is represented by subsampling a formula’s recurrence
\(M_n \longrightarrow M_{kn} \cdot M_{kn+1} \cdot M_{kn+2} \cdot \dotsc \cdot M_{k(n+1) -1} \),
i.e. jumping k steps in the recurrence using only one matrix multiplication, and is identified using the second dynamical metric, the convergence rates of the formulas:
\(r = \lim_{n\to\infty} -\frac{1}{n} \log |\frac{p_n}{q_n} – L| \)
where \(\frac{p_n}{q_n}\) is the nth approximant resulting from the formula, and \( L \) is its limit. Consider for example the following BBP-type series used for efficient computation of digits of \(\pi \) in base-4 [Guillera 2008]
\( \pi = \sum_{k=0}^\infty s_k = \sum_{k=0}^\infty \frac{(-1)^k}{4^k}\left( \frac{1}{4k+3} +\frac{2}{4k+2} +\frac{2}{4k+1} \right) \)
and another series [Barsky et al. 2019]
\( \pi = \frac{1}{4} \sum_{k=0}^\infty \frac{1}{16^k} \left( \frac{8}{8k+1} + \frac{8}{8k+2} + \frac{4}{8k+3} – \frac{2}{8k+5} – \frac{2}{8k+6} – \frac{1}{8k+7} \right) \)
Both have \(\delta = -0.75\). Computing the convergence rates, we get 1.39 and 2.78 suggesting that a fold by 2 of the former is needed to match the formulas. Close inspection reveals that the latter summand is precisely \(s_{2k} + s_{2k+1}\), meaning exactly a fold by 2 of the former, with no additional transformation needed. Folding preserves the limit of the sequence to which it is applied, and in this case suffices, but the general case is more complex and requires the second step of the matching algorithm: UMAPS for solving coboundary.
UMAPS: The coboundary algorithm
The coboundary condition between polynomial recurrences, represented by their matrices \(A(n),B(n)\), stipulates the existence of a polynomial matrix \(U(n)\) and polynomials \(p_A(n),p_B(n)\) such that
\(A(n) \cdot p_A(n)U(n+1) = p_B(n)U(n) \cdot B(n)\)
Which immediately shows one formula can be used to compute the other:
\( \underset{a_n}{\underbrace{\prod_{k=1}^n A(k)}} \propto U(1) \left( \underset{b_n}{\underbrace{ \prod_{k=1}^n B(k) }} \right) U^{-1}(n+1) \)
The products \(p_AU, p_BU\) make reconstruction of the coboundary polynomials a nonlinear problem and the equations are ill-determined without assuming a certain form for the polynomials. UMAPS leverages a necessary condition the coboundary matrix must obey to overcome this nonlinearity with a numerical trick; solving first for \(U(1)\), then finding \(U(2), U(3), U(4), \dotsc\) by propagating \(U(n+1) \propto A^{-1}(n) U(n) B(n)\), and finally reconstructing the coboundary matrix in full via a rational fit to these measurements. The condition is
\(L_A = U(1) L_B\)
where \(L_A\) and \(L_B\) are the projective limits of the formula recurrences. For order-2 recurrences being viewed as continued fractions, \(U(1)(\cdot)\) is the mobius operation defined by \(U(1)\).
Take for example the two series [Amdeberhan et al. 2007; Sun 2022]
\( \frac{\pi}{2} = \sum_{k=1}^\infty \frac{2^k}{k {2k \choose k} } \)
\( \frac{11\pi}{2} + \frac{50}{3} = \sum_{k=1}^\infty \frac{4^k(12k^2 + 1)}{ {4k \choose 2k} } \)
which share \(\delta = -0.65\). These have convergence rates 0.69 and 1.38, so the first is folded by 2, resulting in PCFs with limits \( L_A = \frac{44 – 15\pi}{\pi – 2} \) and \( L_B = \frac{2912 – 5005\pi}{11\pi + 16} \). Solving for \(U(1)\), we get \(U(1) = \begin{pmatrix} -362 & -88270 \\ 19 & 3549 \end{pmatrix}\) (one can verify that \( L_A = \frac{-362\cdot L_B – 88270}{19 \cdot L_B + 3549}\)), and propagating leads to the graphs shown below. As the right graph suggests, a rational fit is successful, and the formulas are coboundary.

Normalizing the empirical coboundary matrix found by propagation enables a rational fit to find the coboundary matrix.
Left: empirical coboundary matrix \(\begin{pmatrix} U_{11}(n) & U_{12}(n) \\ U_{21}(n) & U_{22}(n) \end{pmatrix}\) as a function of \(n\). Right: normalized by \(U_{11}(n)\).
The result is three reversible transformations: two folds \(F_A,F_B\) and a coboundary transformation \(U,p_A,p_B\), that convert one formula into the other, where both are in recurrence form:
\( F_A(A(n)) \cdot p_A(n)U(n + 1) = p_B(n)U(n) \cdot F_B(B(n)) \)
or in other words
\( Cob_{(U,p_A,p_B)}\left(F_A\left(A(n)\right)\right) = F_B\left(B(n)\right) \)
where in our case \(F_A\) is a fold by 2, \(F_B\) is a fold by 1 (identity), \(U(n)\) is a polynomial matrix of degree 10, and \(p_A(n), p_B(n)\) are of degrees 2,1 respectively.
Special results
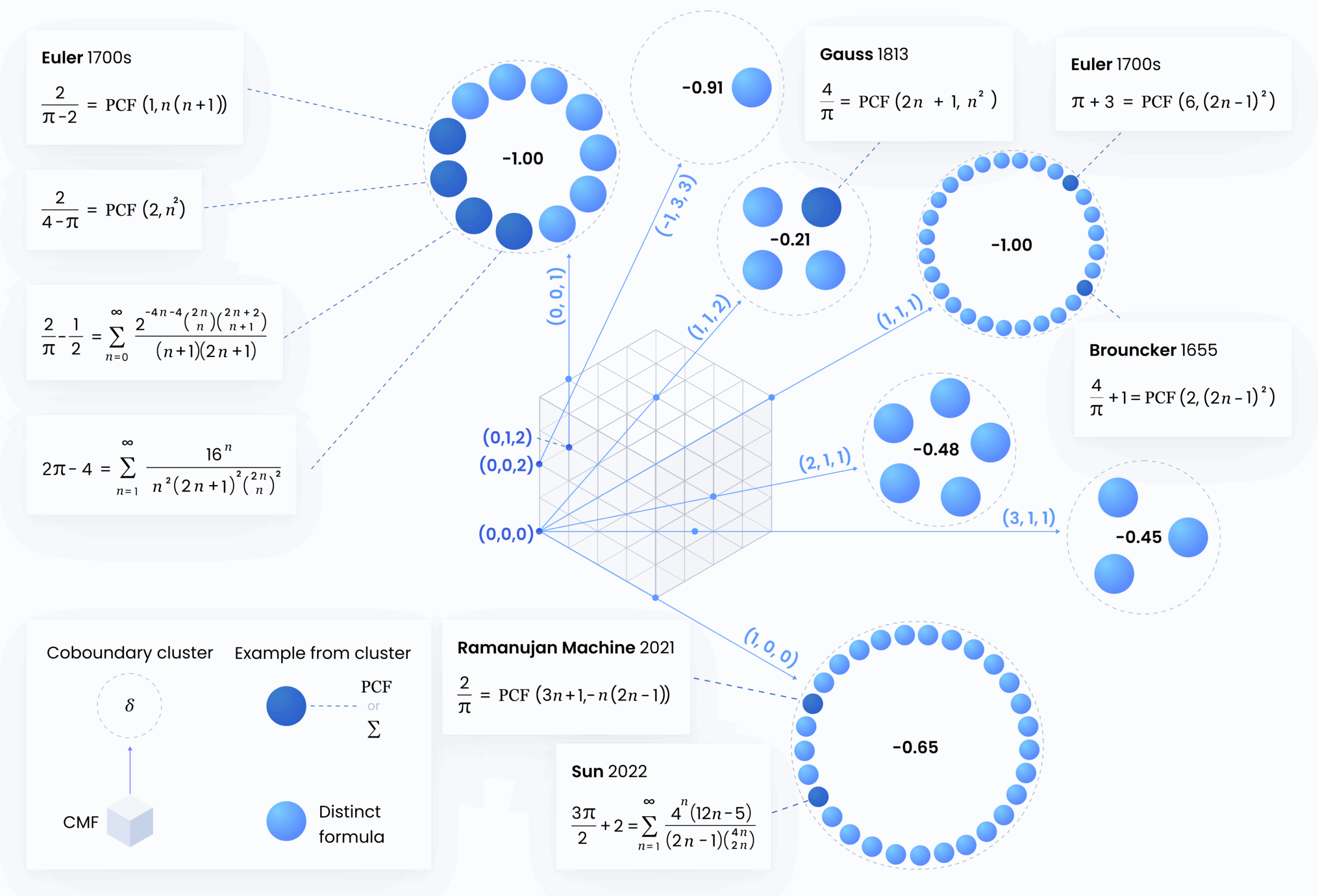
The matching algorithm, powered by UMAPS, merges knowledge contained in formula identities,
and further unifies many formulas in a Conservative Matrix Field (CMF).
Out of 407 formulas collected automatically from the literature, using LLMs for few-shot classification and extraction into SymPy code, 94% were canonicalized or matched with at least one other formula and 43% were matched with formulas arising from the same CMF:
\( M_x = \begin{pmatrix} 1 & y\\\frac{1}{x} & 1 + \frac{x + y – 2 z + 2}{x} \end{pmatrix} \) \( M_y = \begin{pmatrix} 1 & x\\\frac{1}{y} & 1 + \frac{x + y – 2 z + 2}{y} \end{pmatrix} \) \( M_z = \begin{pmatrix} – \frac{z \left(x + y – z\right)}{\left(x – z\right) \left(y – z\right)} & \frac{x y z}{\left(x – z\right) \left(y – z\right)}\\\frac{z}{\left(x – z\right) \left(y – z\right)} & – \frac{z^{2}}{\left(x – z\right) \left(y – z\right)} \end{pmatrix} \)
which proves they are unified by a single mathematical object. In light of the unifying power of this CMF, we call it The \(\pi\) CMF.
A notable example of a connection discovered is between one of Ramanujan’s famous 1914 formulas
\( \frac{3528}{\pi} = \sum_{n=0}^{\infty} \frac{ \left(-1\right)^{n} {\left(\frac{1}{4}\right)}_{\left(n\right)} {\left(\frac{1}{2}\right)}_{\left(n\right)} {\left(\frac{3}{4}\right)}_{\left(n\right)}}{ 882^{2n} n!^{3}} \left(21460 n + 1123\right) \)
and a more recent formula from [Sun 2020],
\( \frac{341446000}{\pi} = \sum_{k=0}^{\infty} \frac{\left(-199148544\right)^{- k} {{2 k \choose k}}^{2} {{4 k \choose 2 k}}}{\left(k + 1\right) \left(2 k – 1\right) \left(4 k – 1\right)} \left(1424799848 k^{2} + 1533506502 k + 108685699\right) \)
These two formulas, discovered a century apart, are now proven equivalent via a simple matrix multiplication discovered by an automated system. Another example is the pair of continued fractions displayed at the top of this article. The continued fractions, respectively discovered by Gauss and by a computer as one of the first automated formula discoveries, are also proven equivalent via the matching algorithm—showing unification of mathematical knowledge across centuries. Diverse symbolic expressions which were collected autonomously are now proven equivalent by a simple set of transformations and matrix multiplications, identified and proven by our algorithm.
Looking forward
The methods provided here are applicable to any constant, demonstrated in our paper for \(\pi \), \(e\), \(\zeta(3)\) and Catalan’s constant. The broader idea of automatically processing vast sources of knowledge with LLMs and pairing such tools with novel algorithms to make new discoveries will likely be a key driving force of mathematics in the budding age of AI, especially if LLMs and other tools begin to take part in algorithm development.